折腾 Ktransformers
最近公司搞来了两台带4个 RTX 4090 的服务器。遂试试在上面弄个 Ktransformers ,尝尝 Deepseek-R1 671B 的威力。
在开始捣鼓 Ktransformers 之前,需要准备好以下东西:
时间和钱- 确定机器上的显卡驱动是最新的,是从 Nvidia 官网下的那个,不是 nvidia-driver 里装的(这个版本有点,可能带不动新版本 cuda)。
- Deepseek R1 的 GGUF,这次我准备的是
unsloth/DeepSeek-R1-GGUF的 Q2_K_L 。 - Deepseek R1 的 config file。这个应该直接 clone deepseek-ai 的 repo 即可。注意不需要 clone 那个贼大的 .safetensors:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/deepseek-ai/DeepSeek-R1 - Docker 镜像
approachingai/ktransformers:v0.3.1-AVX2。因为不想收到 Anaconda 的亲切问候,所以直接用 docker 算了。
上述事项准备好之后,就可以开始折腾了。
0x01 检查 NUMA 设置
给 Ktransformers 设置 NUMA 的目的是在每个 NUMA 节点都存一份权重,让 CPU 可以直接在本 NUMA 节点内直接访问到权重,不用跨节点访问权重,提升性能。但是这样做的缺点也很明显,就是费内存。假如一份权重是100G,你有8个 NUMA 节点的话,那就是要花费 800GB dram 了。所以,这个得看具体情况来……
比如在我的机器上,运行 numastat 可以看见有两个节点。
root@sha-gpu1:~# numastat
node0 node1
numa_hit 26963154 25089482
numa_miss 0 0
numa_foreign 0 0
interleave_hit 4620 4967
local_node 26959124 25003383
other_node 4030 86055
同时我有 1T 内存
root@sha-gpu1:~# free -h
total used free shared buff/cache available
Mem: 1.0Ti 25Gi 963Gi 56Mi 24Gi 981Gi
Swap: 975Mi 0B 975Mi
那么就可以安心上 NUMA 了。
0x02 创建容器
用这个 docker-compose.yml 启动 ktransformers
services:
ktransformers:
image: approachingai/ktransformers:v0.3.1-AVX2
# 因为我的 zen2 既不支持 AMX 也不支持 AVX512,所以用了 AVX2 的。
# 如果CPU有这些指令集,就改成相应的就行~
container_name: ktransformers
runtime: nvidia
environment:
- NVIDIA_VISIBLE_DEVICES=0,1
- TORCH_CUDA_ARCH_LIST=8.9
- DISABLE_TORCHVISION_IMPORTS=1
volumes:
- /mnt/data/models:/mnt/data/models
security_opt:
- seccomp:unconfined
privileged: true
shm_size: "512g"
ports:
- "11434:11434"
restart: unless-stopped
entrypoint: ["tail", "-f", "/dev/null"]
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
随后
docker-compose up -d
这样 ktransformers 环境就启动了。
0x03 安装 NUMA
Ktransformers 的镜像本来是没有 NUMA 的,要在 Docker 容器里面吃上 NUMA ,就要进容器里面再装点东西。
不能在 Dockerfile 里面写 FROM approachingai/ktransformers:v0.3.1-AVX2 RUN balabala 这样子。因为 build 的时候会涉及到显卡,而 docker build 阶段不支持把显卡挂进去。
先 docker exec -it ktransformers 进到容器里面,然后运行
apt-get update -y
apt-get install libnuma-dev libnuma1
USE_NUMA=1 bash ./install.sh
有一个 discussion 说可以加上
USE_BALANCE_SERVE=1来 build。但是我 v0.3.1 实测加上use_balance_serve之后会炸,提示Target "cmTC_45759" requires the language dialect "CUDA20"。
随后下楼去买杯咖啡溜达几圈回来就差不多了。
0x04 开吃!
在容器里面运行下面这个命令来启动 ktransformers.
python -m ktransformers.local_chat \
--model_path=/path/to/models/DSR1-config/ \
--gguf_path=/path/to/gguf/DSR1-Q2KL/ \
--cpu_infer=32 \
--use_cuda_graph=True \
--optimize_config_path=/workspace/ktransformers/ktransformers/optimize/optimize_rules/DeepSeek-V3-Chat.yaml
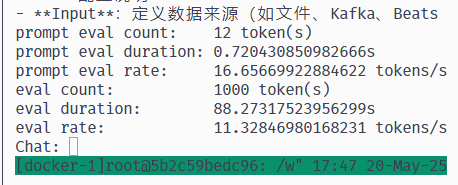
随便问他一点问题,输出结束后会出现速度统计。
在我的这块 zen2 AMD CPU + 4060 跑 deepseek-r1 671b 吐字速度也只有 11 tps ……